Lenguajes de Marca o Etiqueta
La idea de separar en un documento el contenido del formato apareció por primera vez en los años 60. Empieza a utilizarse el concepto de «marca» o «etiqueta» como texto que se añade a los datos y que proporciona información sobre ellos. Un lenguaje de marca seria un modo formalizado de proporcionar estas marcas.
La definición de un lenguaje de marca debe proporcionar:
- Qué marcas están permitidas.
- Qué marcas son obligatorias.
- Como se distinguen las marcas del texto.
- El significado de cada marca.
El primer modo de utilización de marcas que se exploró fueron las marcas procedurales. Se preocupaban sobre todo de la presentación y del formato del texto. Con las marcas procedurales se instruye al agente en qué hacer con el texto y especifica como procesarlo. Entre los lenguajes de marca procedurales se encuentran RTF y PostScript.
A finales de los años 60 la GCA, Graphic Communication Association, crea un comité de estudio que llega a la conclusión de que las marcas deberían ser más descriptivas que procedurales y deberían tener en cuenta la estructura del documento. Las marcas descriptivas, también llamadas generalizadas, además de identificar la estructura del documento se centran en qué es el texto y no especifican los procedimientos que hay que aplicarle.
A finales de los 60 IBM retoma los trabajos de la GCA y crea un lenguaje de marca al que llamaron GML (Generalized Markup Language, que además coincide con las iniciales de sus creadores Goldfarb, Mosher y Lorie). GML estaba basado en las ideas de codificación genérica, pero en vez de tener un simple esquema de etiquetas, introduce el concepto de tipo de documento formalmente definido con una estructura explícita de elementos anidados.
A finales de los 70 ANSI crea un comité para elaborar una norma basada en el lenguaje GML. El primer borrador aparece en 1980. En 1984 ISO se une al grupo de trabajo de ANSI y en1986 SGML (Standard Generalized Markup Language) se convierte en estándar internacional (ISO 8879/1986). «SGML es el estándar internacional para la definición de métodos de representación de textos en forma electrónica, independientes del dispositivo e independientes del sistema».
SGML, más que un lenguaje, es un metalenguaje para la definición y la estandarización de la estructura de los documentos. Define una gramática con la que se pueden crear otros lenguajes de marca. Los lenguajes de marca específicos escritos de acuerdo con los requerimientos de SGML se llaman aplicaciones SGML.
Uno de esos lenguajes derivados de SGML es HTML, Hypertext Markup Language. En 1989, Tim Berners-Lee creó una propuesta de un sistema de documentos hipertexto para ser usado en la comunidad del CERN (Conseil Européen pour la Recherche Nucléaire). Este sistema al que denominó posteriormente «The World Wide Web» perfilaba los componentes básicos necesarios que definen la WWW hoy:
- Ser independiente del sistema.
- Ser capaz de utilizar muchos de los recursos de información existentes y permitir añadir de una manera sencilla nueva información.
- Contar con un mecanismo de transporte de los documentos entre diferentes redes (HTTP).
- Contar con un esquema de identificación para el direccionamiento de documentos de hipertexto tanto local como remoto.
Berners-Lee definió y desarrolló el lenguaje HTML, usando SGML, durante el desarrollo del primer navegador Web. En 1991 puso el código y las especificaciones del sistema, incluyendo HTML, en Internet. Rápidamente empezó a haber navegadores para una amplia variedad de plataformas y según crecía el número de implementaciones, así crecía la variedad de las mismas. El HTML especificado inicialmente (versión 1) se desarrolló más allá de su forma inicial sin que se hubiera creado todavía un estándar real.
HTML 2.0 se convirtió en 1995 en el estándar oficial del lenguaje y fue considerado, en general, una decepción. En aquel año ya estaba en el mercado la versión 2.0 de Navigator, el navegador de Netscape, con implementaciones de marcos y referencias multimedia, muy por encima de las restricciones que imponía el estándar. La especificación estándar de HTML llegó a ser la versión 4.
Sin embargo pronto se puso de manifiesto, sobre todo después de la guerra de etiquetas entre Microsoft y Netscape y con la llegada de las nuevas aplicaciones Web, que eran necesarios medios más flexibles y mejores que los proporcionados por HTML para describir los datos.
En 1996, el W3C, patrocinó un grupo de expertos en SGML para definir un lenguaje de marca con la potencia de SGML y la simplicidad de HTML. Se eliminaron las partes más crípticas de SGML y lo considerado no esencial. El resultado fue la especificación de XML. XML es un subconjunto de SGML y al igual que él, más que un lenguaje de marca es un metalenguaje, es un instrumento para crear otros lenguajes de marca.
Características y Funcionalidades
Podemos considerar dos grupos en los lenguajes de marca: los procedurales y los descriptivos o generalizados.
Los lenguajes de marca procedurales se caracterizan por:
- Contener instrucciones claras para el programa visualizador o impresor sobre la forma en que se debe mostrar el contenido del documento, con un determinado estilo y formato.
- Dependencia de las instrucciones de formateado del medio de presentación, de forma que el documento final, el formado por el contenido original más las marcas, no es portable a otros medios.
Por otra parte, los lenguajes de marca generalizados se caracterizan por:
- Marcar las estructuras del texto: las marcas se dirigen más a describir el contenido del documento, su estructura lógica, que a expresar instrucciones detalladas de formateado.
- Separar la estructura del documento de su aspecto.
- Ser independientes del software que procesa el documento.
- Facilitar el procesamiento automático de la extracción de la información contenida en los documentos.
- Facilitar la generación de visualizaciones y presentaciones del documento: permiten la presentación de diferentes vistas del documento dependiendo del dispositivo de visualización y de las preferencias del usuario.
- Utilizar hojas de estilo: la especificación de cómo presentar las estructuras lógicas, aunque a veces es implícita, generalmente es explícita mediante hojas de estilo del documento.
- Tener soporte para lenguajes de script: permiten el uso de lenguajes de script para añadir funcionalidades no proporcionadas por el lenguaje, generalmente comportamiento interactivo y dinámico.
- Proporcionar medios para determinar si un documento es válido o no, es decir si se ajusta a las reglas gramaticales del lenguaje.
En cuanto a las funcionalidades de los lenguajes de marca generalizados se pueden citar:
- Permiten la publicación de documentos electrónicos en Web.
- Enlace de información a través de enlaces hipertexto, permiten recuperar la información on-line.
- Inclusión de otras aplicaciones, como hojas de cálculo, música, … etc en un documento.
- Diseño de formularios para transacciones electrónicas con otros servicios remotos.
SGML
Dos principios significativos que caracterizan a SGML son:
- Independencia de la representación de la información respecto de los programas y sistemas que la crean y procesan. De aquí su énfasis en las marcas generalizadas o descriptivas, y no procedurales. Con la utilización de marcas descriptivas el mismo documento se puede procesar por software diferente, aplicando diferentes instrucciones de procesamiento a cada una de las partes del documento o el mismo procesamiento a diferentes partes.
- Cubrir la necesidad de tener más de una representación para la misma información: una representación abstracta o lógica de la información y una representación de almacenamiento.
SGML proporciona una herramienta conceptual para el modelado de información estructurada, el documento, y una notación para la representación de estos documentos. Los documentos se representan por medio de tres constructores básicos:
- Los elementos: son bloques estructurales, vistos desde un punto de vista lógico o abstracto, que forman parte del documento (por ejemplo cabeceras, párrafos, tablas, enlaces de hipertexto) y contienen datos, otros elementos subordinados o ambas cosas al mismo tiempo.
- Los atributos: son propiedades asociadas con un tipo de elemento dado cuyo valor describe a un elemento de ese tipo pero que no forman parte de su contenido (por ejemplo la longitud de una tabla).
- Las entidades: son unidades de almacenamiento virtual que contienen una parte del documento o varias partes o el documento completo. SGML define una entidad como una cadena de caracteres que puede ser referenciada como una unidad.
Para obtener la representación abstracta de la información SGML permite definir la estructura de un documento basándose en la relación lógica entre sus partes. Para marcar esta estructura del documento, en vez de considerar un simple esquema de marcas, introduce los conceptos de tipo de documento y definición de tipo de documento (DTD). Lo mismo que cualquier otra clase de objeto procesada por un ordenador, SGML considera que los documentos tienen tipos. El tipo de documento se define formalmente por su estructura lógica, por las partes que lo constituyen. Una definición de tipo de documento es una especificación formal de la estructura de elementos anidados que componen un documento SGML.
La distinción entre la representación lógica y la representación de almacenamiento de la información es inherente al procesamiento de la información (si un documento se representa mediante un único volumen o como varios más pequeños es independiente de su representación lógica; y por otra parte hay propiedades del documento, como su localización, que no se ven afectadas por un cambio en su estructura lógica).
El proporcionar una representación de almacenamiento de la información entra en conflicto con la independencia respecto al sistema. Para resolver este conflicto SGML proporciona la estructura de entidades del documento como un sistema de almacenamiento virtual que interpone entre la estructura de elementos y el sistema real de almacenamiento (el sistema de ficheros, la BD o cualquiera que sea el sistema real).
Como todo lenguaje SGML tiene una sintaxis. El estándar impone unas reglas formales para distinguir las marcas del contenido del documento, y para el uso y colocación de las marcas. Estas reglas constituyen la sintaxis de SGML. Pero el estándar no impone nombres particulares para los elementos del documento, sólo el concepto de elemento (en realidad se le denomina tipo de elemento), ni impone ninguna estructura particular, sólo una definición formal de la estructura cualquiera que sea ésta.
Tipos de sintaxis de SGML. Sintaxis concreta de referencia.
En SGML se han definido dos tipos de sintaxis:
- Una sintaxis abstracta, que en términos de conceptos abstractos, tales como los roles de los delimitadores y de los conjuntos de caracteres, define como se deben construir las marcas SGML.
- Una sintaxis concreta, que define como se han codificado estos conceptos abstractos en una clase específica de documentos SGML.
Dentro del estándar ISO de SGML se ha establecido formalmente una sintaxis concreta particular, las sintaxis concreta de referencia.
La definición formal es la siguiente:

Contiene 8 subcláusulas que definen:
- Los números decimales de los códigos que se van a ignorar porque son caracteres de control (SUNCHAR).
- El conjunto de caracteres de la sintaxis, que consiste en la declaración del conjunto base de caracteres (BASESET), seguido de cómo se van a usar estos caracteres para definir la sintaxis correcta (DECSET). El conjunto base de caracteres es el definido en ISO 646 y el DECSET muestra que los 128 caracteres, empezando en la posición 0 de la lista, deberían asociarse a posiciones idénticas en la sintaxis concreta de referencia.
- Los códigos que representan caracteres de función requeridos por la sintaxis (FUNCTION). Se definen 4 códigos: el fin e inicio de registro, el espacio y el tabulador horizontal.
- Las reglas que se van a aplicar cuando se definen nombres de elementos, atributos o entidades (NAMING). La sintaxis concreta de referencia sólo permite utilizar los caracteres az, A-Z, 0-9, . (punto) y – (guión) para los nombres y tienen que comenzar con un carácter alfabético.Por defecto SGML suponer que los nombres empiezan con un carácter alfabético, seguido de caracteres alfanuméricos. Las en entradas en LCNMSTR y UCNMSTR permiten indicar qué otros caracteres se van a permitir como carácter inicial de los nombres y las entradas en LCNMCHAR y UCNMCHAR qué caracteres no alfanuméricos se pueden utilizar después del carácter inicial. Las entradas en NAMECASE indican que se permite la sustitución de caracteres en minúsculas por caracteres en mayúsculas en los nombres de elementos y marcas relacionadas, pero no en los nombres de entidad, es decir, los nombres de entidad son sensibles al uso de mayúsculas y minúsculas.
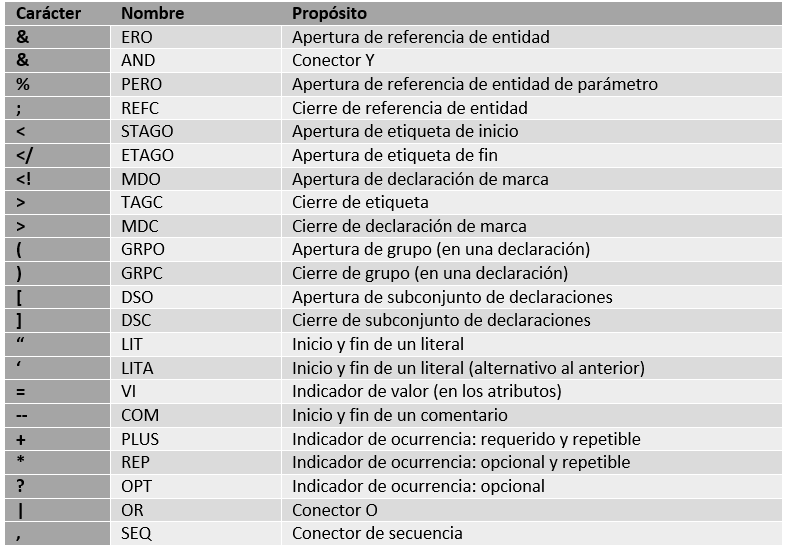
- Los delimitadores de marcas que se van a usar en el documento (DELIM), en este caso, al igual que en las dos subcláusulas siguientes, son los que proporciona SGML por defecto. Algunos de los delimitadores de marca generales proporcionados por defecto se muestran en la tabla siguiente.
- Las palabras reservadas utilizadas en las declaraciones de marcas (NAMES).
- El «conjunto cantidad» (quantity set) requerido por el documento (QUANTITY).
Delimitadores de la sintaxis concreta de referencia:
Estructura de elementos
Marcado genérico. El rol de la DTD.
El principio de marcado genérico o lógico consiste en marcar la estructura de un documento y comprende dos fases:
- La definición del conjunto de marcas que identifican todos los elementos de un documento, junto con la definición del conjunto de reglas que expresan las relaciones entre los elementos y su estructura (esto es el rol de la DTD).
- La introducción de las etiquetas en el contenido del documento de acuerdo a las reglas establecidas en la DTD.
Varias instancias de documento pueden pertenecer a la misma clase de documento, es decir, tener la misma estructura lógica. Para describir la estructura formal de todas las instancias de documento de una determinada clase se construye la Definición de Tipo de Documento o DTD para esa determinada clase.
SGML crea los mecanismos necesarios para describir la estructura de una clase de documentos usando unas declaraciones formales de marcas. Las declaraciones de marcas establecen las marcas que se pueden usar en el documento para delimitar de manera clara y sin ambigüedades su estructura.
Las declaraciones SGML tienen en general la forma siguiente:
<!Palabra_clave Param Param_asociados>
«<!» es el delimitador de apertura de la declaración de marca y «>» es el delimitador de cierre.
Un caso especial son las declaraciones de comentarios que son declaraciones que sólo contienen comentarios:
<!-- Texto del comentario -->
Los dos guiones (–) que son los delimitadores de comentario deben ir inmediatamente después del delimitador de apertura de la declaración de marca e inmediatamente antes del delimitador de cierre, sin espacios en blanco entre ellos.
Palabra_clave puede ser:
- DOCTYPE: mediante esta declaración se define el tipo de documento, que asigna el nombre en Param al conjunto de declaraciones. Este conjunto de declaraciones puede venir justo aquí a continuación encerrado entre [], o estar en otro fichero, que se identifica en Param_asociados, o en una combinación de ambos lugares. Este conjunto de declaraciones engloba a la DTD y puede incluir cualquier otra declaración de marcas que sea necesaria.
- ELEMENT: para declarar un tipo de elemento en la estructura lógica del documento.
- ATTLIST: para asociar un tipo de elemento con un conjunto de características. Estas características se pueden aplicar a una instancia específica de ese tipo de elemento.
- ENTITY: entre otras cosas permite declarar una cadena corta de texto que signifique otra cadena más larga, para sustituir la primera cadena por la segunda cada vez que sea referenciada en una instancia de documento.
- NOTATION: se utiliza para especificar cualquier técnica especial que se necesite cuando se procesa un documento que contiene datos no SGML como por ejemplo un fichero de gráficos.
- SHORTREF: da nombre a un conjunto de asociaciones entre cadenas cortas de caracteres y marcas.
- USEMAP: para activar el conjunto de SHORTREF nombrado en Param con los elementos nombrados en Param_asociados.
Una DTD se expresa en el metalenguaje definido por el estándar SGML y en ella se define la estructura del documento en términos de los elementos que puede contener y el orden en el que estos elementos se pueden presentar. La DTD asigna un nombre a cada uno de esos elementos estructurales, el identificador genérico, por medio del cual se puede reconocer el rol del elemento. Cuando estos identificadores genéricos se colocan entre los delimitadores de marcas forman las etiquetas utilizadas para identificar el inicio y el final de cada elemento.
Una vez definida la DTD se puede marcar la instancia de documento siguiendo las reglas definidas. Se podría marcar un documento sin una DTD formal, simplemente sería necesario un conjunto de etiquetas, pero no se puede comprobar la validez de un documento sin una DTD.
Para poder validar un documento es necesario algún modo de asegurar que se ha marcado sin errores y que la estructura es coherente. Para poder cumplir estos objetivos, en la DTD a parte de dar el nombre de los elementos que se pueden utilizar, sus posibles atributos y valores por defecto para estos atributos, se define también el contenido de cada elemento, el orden en que deben ocurrir estos elementos y cuantas ocurrencias pueden tener, el nombre de las referencias de entidad que se pueden utilizar y si se pueden omitir las etiquetas de inicio o final.
Los documentos SGML se pueden validar utilizando un software especial de análisis denominado parser SGML. Un parser SGML realiza tres tareas:
- Valida la estructura y la validez sintáctica de la propia DTD antes de analizar la instancia del documento para garantizar que no hay ambigüedades en la DTD.
- Analiza la estructura del documento.
- Comprueba si hay errores de marcado en el documento. Un documento sin errores se dice que ha sido validado.
Elementos. Declaración de tipos de elementos.
El rol de un elemento SGML depende del contexto en el que se encuentre. Tenemos dos roles principales:
- Elemento documento base. Es el primer elemento especificado en cualquier documento SGML. Este elemento debe ser formalmente declarado mediante una entrada de declaración de tipo de elemento que tenga el mismo nombre que el de la declaración de tipo de documento.
- Elementos anidados. Se pueden anidar otros elementos entre las dos etiquetas que identifican los límites del elemento documento base. El nivel de anidamientos que se pueden tener depende de la sintaxis concreta que se esté siguiendo. En la sintaxis concreta de referencia se pueden usar hasta 24 niveles de anidamiento.
Una declaración de tipo de elemento tiene la forma:
<!ELEMENT nombre_elem n m modelo>
donde:
- nombre_elem: es el nombre del tipo de elemento (su identificador genérico) que lo identifica de manera única.
- n m: son los modificadores de minimización. Son reglas para incluir u omitir las etiquetas de inicio y fin respectivamente. Un – (guión) indica que la etiqueta (de inicio o fin) es obligatoria y una o (mayúscula o minúscula) que es opcional.
- modelo: es bien una declaración formal del tipo de datos que puede contener el elemento, bien un modelo de contenido, que muestra que subelementos pueden o deben formar parte del tipo de elemento que se está declarando.
Cuando varios tipos de elementos comparten el mismo contenido y modificadores de minimización se puede sustituir el nombre del tipo de elemento por un grupo de nombres que es un conjunto de nombre de tipo de elemento conectados, generalmente por conectores OR, y encerrados entre paréntesis:
<!ELEMENT (nombre_elem1 | ... | nombre_elemN) n m modelo>
Cuando un elemento puede contener subelementos se debe definir el modelo de contenido como un grupo de modelo. Los grupos de modelo son uno o más nombres de tipos de elementos unidos mediante conectores de ordenación y encerrados entre paréntesis.
Los conectores de ordenación se utilizan para especificar un orden en un grupo y son:
- , (coma) conector de secuencia: especifica una secuencia estricta.
- & conector AND: se permite cualquier orden.
- | conector OR: puede aparecer uno y sólo uno (o exclusivo).
Los grupos de modelo utilizan además indicadores de ocurrencia. Los indicadores de ocurrencia modifican a un grupo o a un elemento individual y son:
- ?: opcional, 0 ó 1.
- +: requerido y puede repetirse, 1 ó más.
- *: opcional y puede repetirse, 0 ó más.
La ausencia de uno de estos indicadores implica que el elemento, o grupo de elementos, tiene que ocurrir una vez y sólo una.
Los indicadores de ocurrencia tienen una precedencia mayor que los conectores de ordenación.
Para indicar en los modelos de grupo un punto en el cual el elemento puede contener texto se utiliza el indicador de nombre reservado, #, seguido de PCDATA (parsed character data). #PCDATA indica que en ese lugar del modelo el elemento contiene texto que ha sido comprobado por el parser SGML para asegurar que se han identificado todas las marcas y las referencias de entidad.
Cuando un elemento no tiene subelementos, su contenido se puede declarar como uno de los siguientes tipos de contenidos declarados:
- RCDATA (replaceable character data): puede contener texto, referencias de carácter (una referencia que es reemplazada por un único carácter) o referencias de entidad que se resuelven en caracteres válidos SGML.
- CDATA (character data): contiene sólo caracteres válidos SGML.
- EMPTY: no tiene contenido.
Para los elementos con contenido declarado, la palabra clave sustituye al grupo de modelo, incluyendo los paréntesis.
Los grupos de modelo se pueden calificar añadiendo listas de excepciones. Hay dos tipos de excepciones:
- Excepciones de exclusión: identifican elementos que no se pueden utilizar mientras el elemento actual esté sin cerrar.
- Excepciones de inclusión: definen elementos que se pueden incluir en cualquier punto en el grupo de modelo.
Atributos. Declaración de listas de definición de atributos.
Un atributo es un parámetro nominado que se utiliza para calificar un elemento. Se introduce en la etiqueta de inicio del elemento.
Hay dos partes en la especificación de un atributo, su nombre y su valor, que se unen mediante un indicador de valor (=):
<nom_elemen nom_atrib="valor_atrib">
Los atributos se declaran en declaraciones de listas de definición de atributos. Su formato es:
<!ATTLIST elem_asoc definicion_atrb1 ............... definicion_atrbN>
donde elem_asoc es el elemento al que se asocia la lista de atributos y cada definicion_atrib es la definición de un atributo.
Cada definición de atributo consiste en un nombre de atributo, un valor declarado y un valor por defecto, separados entre ellos por carácter separador.
Una valor declarado puede ser un nombre reservado que identifica el tipo de valores que se pueden introducir o una lista de valores de atributo encerrada entre paréntesis.
Los nombres reservados que se pueden utilizar para los tipos de valores son:

Un valor por defecto es o bien un valor específico o uno de los nombres reservados siguientes:

Estructura de Entidades
La estructura de entidades es un modelo virtual de almacenamiento que permite dividir un documento arbitrariamente para facilitar su gestión. Es virtual porque no hay relación uno a uno entre las entidades y los objetos reales de almacenamiento.
La estructura de entidades es independiente de la estructura de elementos.
Entidades. Tipos de entidades.
SGML define una entidad como una cadena de caracteres que puede ser referenciada como una unidad.
Un documento SGML completo es una entidad llamada entidad documento SGML y que pueden contener referencias a otras entidades.
Cada entidad embebida en una entidad de documento SGML tiene dos componentes: una declaración de entidad y una o más referencias de entidad. La declaración de entidad define el nombre y el contenido de la entidad. Las referencias de entidad identifican los puntos en los que el contenido se va a introducir en el documento.
Hay dos tipos principales de entidades:
- Entidades generales: contienen datos que van a formar parte de un documento. Se pueden referenciar en la instancia de documento o en el texto de sustitución de las declaraciones de otras entidades generales.
- Entidades de parámetro: contienen caracteres que se necesitan como parte de alguna declaración SGML. Se pueden referenciar sólo en las declaraciones de marcas.
Ambas categorías se pueden subdividir en:
- Entidades externas: el texto de sustitución está definido por referencia a un identificador SYSTEM (datos que especifican el identificador del fichero, su localización y cualquier otra información que permitan localizar la entidad) o PUBLIC (un literal que identifica texto público, es decir, que es conocido más allá del contexto de un único documento o de un entorno de un sistema), es decir, el texto está almacenado en un fichero separado.
- Entidades internas: el texto de sustitución está definido dentro del prólogo.
En la sintaxis concreta de referencia las referencias de entidad general tienen la forma &nombre_entidad; o simplemente &nombre_entidad si va seguida de un espacio en blanco de un código de final de registro; y las referencias de entidad de parámetro %nombre_entidad; o %nombre_entidad.
Entidad documento SGML
Una entidad documento SGML tiene tres secciones:
- Una declaración SGML (opcional). Es la parte de un documento SGML donde se define el esquema de codificación utilizado en su preparación. En la declaración se especifica, entre otras cosas, el conjunto de caracteres que se está utilizando y los caracteres usados para delimitar las marcas. Para los documentos que se transmiten sin la declaración SGML, llamados documentos básicos SGML, se asume que la declaración es la proporcionada por el estándar ISO de SGML para un documento básico típico.
- Un prólogo de documento. Contiene la definición de las estructuras del documento (la DTD) y otra información relacionada. La indicación de qué DTD se está usando en el documento se hace por medio de una declaración de tipo de documento (declaración DOCTYPE).
- Una instancia de documento. Es el contenido, más las marcas, del documento.
Un ejemplo muy simple de documento SGML es el siguiente:

Declaración de entidades
Las declaraciones de entidades generales tienen la forma:
<!ENTITY nombre_entidad texto_de_sustitución>
El texto de sustitución puede tener códigos de marcas, referencias a otras entidades, referencias de carácter, etc. que se interpretan cuando se añade el texto de sustitución al documento.
Hay variaciones de esta declaración básica, entre ellas las que permiten especificar:
- Entidades que contienen sólo datos de carácter que no deberían incluirse en un análisis de marcado. Esto se hace incluyendo la palabra clave CDATA entre el nombre de la entidad y su texto de sustitución. Esto significa que los caracteres dentro de la cadena de sustitución que posiblemente podrían ser interpretados como marcas serán ignorados.
- Entidades que contienen texto de sustitución específico del sistema. Para ello se incluye la palabra clave SDATA entre el nombre de la entidad y su texto de sustitución.
- Una entidad por defecto cuyo texto se usará cuando se referencia a una entidad cuyo nombre no se reconoce como una de las entidades declaradas. Esto se hace sustituyendo en la declaración nombre_entidad por la palabra reservada #DEFAULT.
Las declaraciones de entidades de parámetro tienen la forma:
<!ENTITY % nombre_entidad texto_de_sustitución">
Generalmente el texto de sustitución está formado por una serie de nombres de tipos de elemento separados por conectores de ordenación.
Las entidades de parámetro tienen que declararse antes de que sean referenciadas.
DSSSL
DSSSL (Document Style Semantics and Specification Language) definido en el estándar ISO/IEC 10179:1996 proporciona un mecanismo de propósito general para transformar documentos y para asociar instrucciones de formateado a documentos codificados utilizando SGML, tanto on-line como off-line.
DSSSL tiene dos componentes principales:
- Un lenguaje de transformación. Se utiliza para especificar transformaciones estructurales sobre ficheros fuente SGML, por ejemplo, como se fusionan dos o más documentos, como se generan índices o tablas de contenido, etc.
- Un lenguaje de estilo. Se utiliza para especificar el formato de una manera independiente de la plataforma. Para hacer posible una implementación limitada del lenguaje de estilo, dentro de él se creó CQL (Core Query Language) y CEL (Core Expression Language), que no contienen ciertas características del lenguaje de estilo designadas como opcionales.
HTML
Como ya se ha comentado HTML es una aplicación de SGML que ha sido establecio como estándar internacional (ISO/EIC 15445:2000). HTML se utiliza para la publicación de documentos en Web y para definir la estructura de los elementos y los enlaces entre ellos.
Entre las características y reglas básicas de HTML están:
- Los documentos tienen una estructura bien definida.
- Los documentos se estructuran utilizando elementos.
- La mayoría de los elementos son pares de etiquetas: una etiqueta de inicio y una de cierre. Algunos elementos tienen etiquetas de cierre opcionales y otros tienen una única etiqueta de apertura.
- Las etiquetas tienen la forma <nom_elem> o <nom_elem></nom_elem>
- Las etiquetas deben estar anidadas, no cruzadas.
- Los elementos pueden tener atributos: <nom_elem nom_atributo=»valor»>. El valor del atributo debería ir entre comillas.
- Los nombres de elementos no son sensibles al uso de mayúsculas o minúsculas pero sí podría serlo el valor de los atributos.
- Los navegadores ignoran los elementos o atributos desconocidos.
- Los navegadores colapsan los espacios en blanco a un único espacio, esto incluye a los tabuladores, saltos de línea y retorno de carro.
Estructura de un documento HTML
De la DTD de cualquier versión de HTML se puede derivar una plantilla básica para un documento HTML:

La primera línea, la declaración DOCTYPE, muestra la DTD que se sigue en el documento. Dentro de la etiqueta <html> se incluyen las dos secciones principales que tiene un documento HTML: la cabecera y el cuerpo. La cabecera contiene el título y otra información complementaria sobre el documento. En el cuerpo es donde va el contenido del documento con las marcas asociadas a su estructura y quizá presentación.
Todo documento debe contener una etiquete de inicio de documento al principio, <html> y una etiqueta de fin de documento, </html> al final del documento. Contiene un único elemento HEAD y un único elemento BODY.
Las etiquetas <head> y </head> marcan el inicio y el final de la cabecera.
Las etiquetas <body> y </body> marcan el inicio y fin del cuerpo. El elemento body delimita el contenido del documento y sus atributos se utilizan para efectuar cambios que afecten al documento entero como por ejemplo establecer imágenes o colores de fondo.
En el body están incluidos los elementos de bloque estructurado como encabezamientos, párrafos, listas y tablas. Además contiene también elementos de nivel de texto. Sin embargo, aunque la definición de la presentación física de esa estructura lógica debería estar definida en otro sitio (en hojas de estilo por ejemplo), HTML no es un lenguaje de marcado lógico puro y tiene etiquetas físicas que se pueden utilizar para formatear y dar un aspecto determinado al contenido del documento.
Elementos de la cabecera del documento
Según la especificación estricta, los elementos que pueden aparecer en la cabecera son: base, link, meta, script, style y title.
El elemento title da un título al documento. Cuando se visualiza el documento en un navegador el título aparece en la barra del mismo. Su sintaxis es: <title>titulo_documento</title>.
Todo documento debe tener exactamente un elemento tiltle en la cabecera. El título puede contener texto plano y referencias de carácter. No se permite ninguna otra marca.
El elemento style embebe una hoja de estilo en el documento y la cabecera puede contener cualquier número de ellos. Tiene un atributo obligatorio, type, más otros opcionales. El atributo TYPE especifica el tipo de contenido del lenguaje de estilo. Por ejemplo, para CSS (Canscading Style Sheets) el valor del atributo debería ser «text/css».
Las reglas de estilo se especifican entre la etiqueta de inicio <style> y la etiqueta de fin </style> como se fuera una declaración de comentario:
<style type="tipo_contenido">
<!--
REGLAS DE ESTILO
-->
</style>
El elemento script incluye un script de cliente en el documento. La cabecera puede contener cualquier número de elementos script (se permiten también en el body).
Tiene un atributo obligatorio, type, para especificar el tipo de contenido del lenguaje de script, por ejemplo «text/javascript». Este atributo ha sustituido al atributo language en versiones anteriores, que se mantiene en esta versión como «desaprobado» (deprecated), donde se especifica el nombre del lenguaje.
Un script embebido se da como el contenido del elemento script y debe ir como si fuera una declaración de comentario:
Mediante el atributo opcional src se permite especificar la localización de un script externo, ya sea local o remoto. En este caso si hubiera un script embebido se ignora.
El elemento meta especifica pares nombre-valor para proporcionar metainformación sobre el documento, link especifica una relación entre el documento actual y otros recursos y base proporciona una dirección base para interpretar URLs relativas.
Marcas Básicas
Antes de comenzar a examinar las principales marcas decir que en HTML 4 se han añadido tres conjuntos de atributos a prácticamente todos los elementos.
Un primer conjunto de cuatro atributos, que se usan sobre todo en las hojas de estilo y lenguajes de script:
- id: asigna un nombre único en el documento al elemento.
- class: indica la clase o clases a las que pertenece el elemento (usado en hojas de estilo).
- style: añade información de hoja de estilo directamente en la etiqueta.
- title: se utiliza para dar un texto de aviso sobre un elemento o su contenido.
Se ha añadido también un conjunto de atributos manejadores de eventos para poder añadir código de scripts que se definen en múltiples elementos. Los manejadores de eventos son: onclick, ondblclick, onkeydown, onkeypress, onkeyup, onmousedown, onmousemove, onmouseup, onmouseover y onmouseout.
El último grupo está relacionado con los distintos idiomas. Los dos atributos que contempla son dir, que permite indicar la dirección del texto como ltr (de izquierda a derecha) o rtl (de derecha a izquierda); y lang que permite indicar el idioma utilizado.
Elementos de nivel de bloque
Párrafos y saltos de línea
El elemento <p> indica un párrafo. Generalmente el navegador incluye una línea antes y después del párrafo. Como los encabezamientos, tiene un atributo align para indicar el alineamiento.
La etiqueta <br> inserta un salto de línea en el documento. <br> es un elemento vacío así que no tiene etiqueta de cierre.
Divisiones y texto preformateado
La etiqueta <div> se utiliza para estructurar un documento en secciones o divisiones. Tiene el atributo align que puede valer right, left o centre para alinear el texto a la derecha a la izquierda o centrado. Existe una etiqueta que es un alias para el elemento div alineado en el centro: <centre>.
La etiqueta <pre> se utiliza para indicar texto preformateado. El texto entre las etiquetas de inicio y fin de pre conservan todos los espacios en blanco, tabuladores y saltos de línea.
Listas
HTML tiene tres tipos de listas:
- Ordenadas: se marcan con <ol> y generalmente se presentan como un esquema numerado.
- No ordenadas: se marcan con <ul>. Los navegadores generalmente añaden algún símbolo a cada ítem (un círculo o un cuadrado) y añaden una sangría.
- De definición: se marcan con <dl>. Las listas de definición son listas de pares término-definición, es decir, un glosario.
Las listas ordenadas y no ordenadas se pueden anidar y los elementos en la lista se definen utilizando la etiqueta <li>. En las listas de definición cada término se marca con <dt> y cada definición con <dd>. No se requiere etiqueta de cierre para estos elementos.
Las listas ordenadas tienen tres atributos:
- compact: sugiere al navegador que intente compactar la lista.
- type: establece el esquema de numeración para la lista. Toma los valores «a» para letras minúsculas, «A» para mayúsculas, «i» para números romanos en minúsculas, «I» para números romanos en mayúsculas y «1» para números (es el valor por defecto).
- start: indica el valor para comenzar la numeración de la lista. Este valor es numérico incluso aunque se hubiera indicado en type un numeral.
Tablas
Una tabla se marca con el par de etiquetas <table></table>. Una tabla está compuesta de filas y las filas de celdas. Cada fila se marca con <tr></tr>. Las celdas pueden ser de datos, <td></td>, o cabeceras, <th></th>. El número de filas de la tabla lo determina el número de elementos tr que contenga y el número de columnas el máximo entre los números de celdas de cada fila.
Por medio de los atributos colspan y rowspan de los elementos de la tabla se pueden indicar celdas que se expandan al número de columnas o filas indicado.
Se puede especificar la anchura de la tabla mediante el atributo width de table y el grosor del borde con border. Los atributos cellpadding y cellspacing controlan el espacio entre celdas y el espacio entre el borde de la celda y su contenido respectivamente.
Elementos de nivel de texto
Los elementos de nivel de texto pueden ser físicos y lógicos. Los físicos especifican como debería presentarse el texto, los lógicos se centran en lo qué es el texto y no en su aspecto.
Elementos físicos típicos son: <b></b> para negrita; <i></i> para itálica, <sub></sub> para subíndice.
Elementos lógicos son: <cite></cite> para citas (se suele mostrar en itálica>; <em></em> para énfasis (también se muestra en itálica); <strong></strong> para mayor énfasis (se suele mostrar en negrita).
Otros elementos y entidades
Encabezados
Los elementos de encabezamiento se utilizan para crear cabeceras en el contenido del documento. Hay seis niveles desde <h1> a <h6>. Su principal atributo es align que permite indicar los valores left (por defecto), right, center o justify para alinear el texto a la izquierda, a la derecha, centrado o justificado respectivamente.
Imágenes
Para insertar una imagen se utiliza la etiqueta <img> con el URL de la imagen en el atributo src. Mediante el atributo alt se puede especificar un texto alternativo que se muestra mientras se está cargando la imagen o si esta no puede cargarse. Con los atributos height y width se dan la altura y la anchura a la imagen; y con hspace y vspace se especifica un espacio horizontal a la derecha y a la izquierda de la imagen, y un espacio vertical encima y debajo de la imagen. También se puede especificar como se alineará el texto alrededor de la imagen. Para esto se utiliza el atributo align con posibles valores top, middle, bottom, left y rigth.
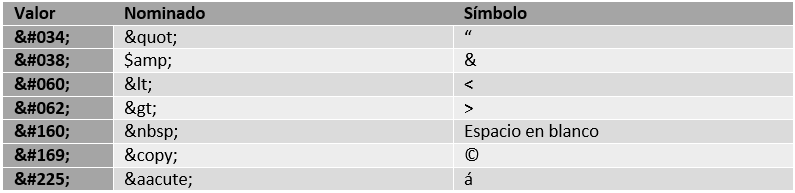
Entidades de carácter
Para poner caracteres especiales en el texto (letras acentuadas, espacios en blanco que no se colapsen, etc) se utilizan las entidades de carácter. Se referencian mediante &codigo; donde código es un valor numérico o una palabra que indican el carácter real que se quiere poner en el contenido. En la siguiente tabla se dan algunas de estas entidades:
Formularios
Los formularios en HTML están contenidos en un elemento form. Un formulario está compuesto de campos y de las marcas necesarias para estructurarlo y controlar su presentación. Cada uno de los campos se identifica de manera única dentro del formulario por el valor en el atributo name o id.
Dentro de la etiqueta <form> se deben identificar dos cosas: la dirección del programa que lo va a manejar, por medio del atributo action, y el método que se va a utilizar para pasar los datos a ese programa, mediante el atributo method. En action generalmente se especifica la URL del programa. El valor de method puede ser GET o POST (métodos de HTTP).
Los principales campos del formulario incluyen: campos de texto, campos de password, campos de texto multilínea, radio buttons, check box, menús desplagables y botones.
Los campos de texto se especifican por medio de una etiqueta <input> (el elemento input no tiene etiqueta de cierre) y el atributo type igual a «text». El tamaño del campo y el número máximo de caracteres que puede contener establecen con los atributos size y maxlength respectivamente. Además se puede establecer un valor por defecto para el campo con el atributo value. Si el atributo type se pone como «password» tenemos un campo de password en los que no se tiene eco de los caracteres tecleados.
Los campos de texto multilínea se definen con el elemento textarea. El número de líneas lo determina el valor del atributo rows y el número de caracteres por línea el atributo cols. El texto por defecto es el contenido del elemento, es decir, el texto que va entre la etiqueta de apertura <textarea> y de cierre </textarea>, que debe ser texto sin incluir ninguna marca HTML. En este texto sí se conservan todos los espacios en blanco, saltos de línea y otros caracteres de control.
Para crear un menú desplegable, que permitan seleccionar una opción entre varias posibles, se utiliza la etiqueta <select>. Las opciones se indican con elementos option dentro del elemento select. El valor enviado cuando se envía el formulario es el valor entre las etiquetas de inicio y fin de option, pero si se incluye el atributo value, su valor será el que se transmita. El número de opciones mostradas se establece con el atributo size de select que por defecto vale 1. Incluyendo el atributo multiple en select convertimos al menú en una lista en la que se puede elegir más de una opción.
La etiqueta input también se utiliza para crear check-boxex y radio buttons, estableciendo el valor del atributo type a checkbox o radio. En elcaso de los radio buttons, todos los que se quiera que estén dentro del mismo grupo, es decir, que cuando se seleccione uno del grupo se elimine la selección anterior dentro del grupo, deben tener el mismo valor en el atributo name.
Los botones se definen con el elemento input y type=»button». No tienen ninguna acción predefinida. Para definir una acción se utilizan los atributos manejadores de evento mencionados con anterioridad y los lenguajes de script. Por ejemplo:
<input type="button" value="Pincha" onclick="alert('Mensaje');"/>
Dentro de un campo del formulario también es posible indicar el nombre de un fichero que se quiere cargar en el servidor. Para ello se utiliza el elemento input con type=»file». Esto crea un campo de texto donde introducir el nombre del fichero y un botón a la derecha del campo generalmente etiquetado como examinar (o browse) que al pulsarlo permite examinar el sistema de archivos local para encontrar el fichero que se quiere enviar al servidor.
Una vez que se ha rellenado el formulario necesitamos un medio para decir al navegador que lo envíe, este medio se proporciona de nuevo con el elemento input. Estableciendo type a submit, se crea un botón que al ser pinchado hace que el navegador envíe los datos a la dirección especificada en action. En el atributo value se establece el texto que va a aparecer en el botón y además se envía al servidor. Si el valor de type es reset se crea también un botón pero su función es limpiar el formulario y establecer los valores por defecto que se hayan podido especificar.
Direccionamiento y enlaces
En HTML la forma de definir hiperenlaces es mediante la etiqueta <a> (en hipertexto los extremos de los enlaces generalmente se les denomina anclas – anchors) que tiene un atributo href para indicar la dirección del recurso que se quiere enlazar. El contenido entre las etiquetas de inicio y fin del elemento es el hiperenlace que se activa al pinchar en él. El contenido puede ser texto o una imagen.
Un posible destino del hiperenlace es una localización dentro del propio documento. Se necesita alguna forma de poder marcar esa localizavión para luego referenciarla en href. También se usa la etiqueta <a> para definir estas localizaciones mediante un uso especial de la misma denominado establecimiento de identificador de fragmento o simplemente marcador.
Para establecer un marcador se coloca una etiqueta <a> en la localización y va a ser el valor del atributo name el que determine el nombre simbólico para poder referenciarla. La forma de referenciar esta localización es mediante el valor «#marcador» en el href. Por ejemplo:
<p><a name="inicio"></a> Esto es el inicio</p> ..... <p><a name="fin" href="#inicio">Ir a inicio</a></p>
XML y sus extensiones
Como ya se ha comentado, XML (Extensible Markup Language) es una recomendación del W3C desde 1998, creada como subconjunto de SGML que aprovecha su potencia y flexibilidad eliminando parte de su complejidad. Como metalenguaje se puede utilizar para la definición de otros lenguajes de marcas. Por ejemplo se ha escrito HTML basándose en XML, dando lugar a la especificación XHTML. Otros lenguajes derivados de XML son WML (Wireless Markup Languages), SOAP (Simple Object Access Protocol) o MathML (Mathematical Markup Language).
Los objetivos del diseño de XML, citados en la especificación, eran:
- Ser directamente utilizable en Internet.
- Soportar una amplia variedad de aplicaciones.
- Compatibilidad con SGML.
- Facilidad de creación de programas que procesen documentos XML.
- Mantener el número de características opcionales al mínimo, idealmente ninguna.
- Los documentos deberían ser legibles por humanos y razonablemente claros.
- El diseño debería ser preparado rápidamente.
- Diseño formal y conciso.
- Facilidad de creación de documentos XML.
- Importancia mínima de la concisión y refinamiento de las marcas.
Cada subconjunto de SGML, XML no contempla ciertas características de SGML. Podemos citar entre las diferencias:
- Respecto a la sintaxis, en XML:
- Los nombres pueden utilizar caracteres Unicode y no se restringen a ASCII.
- Se permiten _ y : en los nombres.
- Los nombres son sensitivos al uso de mayúsculas y minúsculas.
- El delimitador de cierra de las instrucciones de procesamiento es ?>.
- No se permiten marcas de inicio sin cerrar.
- Respecto a la declaración de elementos, atributos y entidades impone ciertas restricciones no presentes en SGML, como son:
- Las referencias de entidad y de carácter deben terminar en ;.
- No se permiten referencias a entidades externas de datos en el contenido.
- En las declaraciones de elementos no se permiten grupos de nombres, ni contenido declarado como CDATA o RDATA, si se pueden utilizar exclusiones o inclusiones. Además no se puede utilizar un grupo de nombres como tipo de elemento y en los modelos de contenido no pueden utilizar el conector AND.
- En las declaraciones de listas de definición de atributos no se permiten atributos CURRENT, no se puede utilizar un nombre de grupo como elemento asociado y los valores especificados por defecto deben ser literales.
Hoy en día XML ha alcanzado un alto grado de utilización por los beneficios que ofrece, entre ellos:
- Simplicidad: la información codificada en XML el legible visualmente y puede ser procesada sin dificultad por los ordenadores. XML es fácil de entender, implementar y usar.
- Aceptabilidad de uso para transferencia de datos: XML no es un lenguaje de programación, es un forma estándar de poner la información en un formato que pueda ser procesado e intercambiado por diversos dispositivos de hardware, SO, aplicaciones de software y la Web.
- Uniformidad y conformidad: cuando se quiere integrar dos aplicaciones, la organización y los expertos técnicos deben decidir si se integran los sistemas o se modifica la arquitectura de las aplicaciones. Si los datos de ambas aplicaciones están de acuerdo en el formato y se pueden transformar fácilmente de uno a otro, los costes de desarrollo se pueden reducir. Si este formato común se puede basar en un estándar ampliamente aceptado entonces las interfaces entre aplicaciones se hacen menos costosas.
- Separación de los datos de su visualización: sin las separación de datos la reutilización de los mismos en múltiples intefaces de usuario sería difícil.
- Extensibilidad: como se deduce de su nombre, XML fue diseñado desde el principio para permitir extensiones.
Podemos considerar dos ámbitos fundamentales de aplicación de XML:
- Compartir información: el problema principal a la hora de compartir información entre dos organizaciones cualesquiera es la interfaz entre ellas. Los beneficios de tener un formato común para compartir información entre dos organizaciones cualesquiera son obvios. Sobre XML se han construido tecnologías y estándares. Consorcios y organizaciones empresariales han desarrollado formatos y estandarizaciones XML. En diciembre de 2000 la UN/CEFACT y OASIS se unieron para iniciar un proyecto para estandarizar especificaciones XML para negocios. La iniciativa, llamada XML para negocio electrónico (Electronic Business XML, ebXML) desarrolló un marco técnico que permite utilizar XML para todo el intercambio de datos de negocio electrónico.
- Almacenamiento, transmisión e interpretación de los datos: si el almacenamiento de la información se puede adaptar a varios medios, éste se dirigirá al medio que tiene menor coste. XML está basado en texto, que obviamente es admitido por todos los medios de almacenamiento, y su coste de almacenamiento es barato comparado con los necesarios para el almacenamiento de los gráficos. Al igual que el coste de almacenamiento de estos objetos basados en texto es barato, también lo es su transmisión. Además como es comúnmente aceptado, al adherirse a estándares internacionales, puede ser fácilmente interpretado.
La recomendación XML viene acompañada de otras especificaciones como son XLS, para la creación de hojas de estilo, XLink y XPointer para la creación de enlaces con otros recursos.
Documentos XML
Documentos válidos y documentos bien formados
XML distingue entre documentos bien formados y válidos.
Un documento es un documento XML bien formado si:
- Contiene uno o más elementos.
- Tiene exactamente un elemento raíz (o elemento documento) caracterizado por que ninguna de sus partes aparece en el contenido de ningún otro elemento, es decir, debe contener un par único de etiquetas de apertura y de cierre que contengan al documento completo.
- Para el resto de elementos si su etiqueta de inicio están en el contenido de otro elemento su etiqueta de cierre debe estar en el contenido del mismo, o lo que es lo mismo, los elementos deben estar anidados apropiadamente sin permitir cruces entre estos anidamientos.
- Obedece todas las restricciones de forma (web-formedness constraints) dadas en la especificación XML.
- El contenido de todas las entidades analizables (parsed entities) está bien formado.
Una entidad analizable es aquella cuyo contenido se considera parte integrante del documento. Una entidad no analizable es un recurso cuyo contenido puede o no se texto, y si es texto puede ser otro que no sea XML.
Algunas de las restricciones son las siguientes:
- Todos los elementos, menos los vacíos, deben llevar etiquetas de apertura y cierre.
- Los elementos vacíos, sin contenido, se marcarán con la etiqueta <elem_sin_cont/>
- Los valores de atributos van siempre entre comillas simples (‘) o dobles («)
- Los nombres son sensibles al uso de mayúsculas y minúsculas. Deben comenzar por una letra, _ o :.
Según se define en la especificación, un documento es documento XML válido si:
- Tiene asociada una declaración de tipo de documento.
- Cumple todas las restricciones expresada en la declaración de tipo de documento.
Para comprobar la validez de los documentos, o si están bien formados, se utilizan los procesadores XML, que son módulos de software que leen el documento XML y proporcionan acceso a su contenido y estructura a la aplicación XML para la que el procesador está haciendo el análisis.
En la especificación se distingue entre procesadores con validación y sin validación. Ambos deben informar de las violaciones a las restricciones de la especificación en la entidad documento y en cualquier otra entidad analizable que puedan leer. Los procesadores con validación deben además informar de las violaciones a las restricciones expresadas en las declaraciones de la DTD y a las restricciones de validación dadas en la especificación.
Componentes de un documento XML
Un documento XML consta de un prólogo que contiene toda la información relevante del documento que no sean marcas ni contenido, y el cuerpo del documento que contiene al menos el elemento raíz.
El prólogo contiene:
- Una declaración XML. Es la sentencia que declara al documento como un documento XML.
- Una declaración de tipo de documento. Enlaza el documento con su DTD o el DTD puede estar incluido en la propia declaración o ambas cosas al mismo tiempo.
- Uno o más comentarios e instrucciones de procesamiento.
Según la especificación el prólogo debe ir antes del primer elemento del documento pero puede estar vacío, es decir, todas las componentes nombradas anteriormente son opcionales, no son necesarias para tener un documento XML bien formado.
La declaración de documento es una instrucción de procesamiento (las instrucciones de procesamiento permiten incluir en un documento instrucciones para aplicaciones propietarias; sus delimitadores de inicio y fin de etiqueta son <? y ?> respectivamente, tiene la forma:
<?xml version="version_xml" encoding="tipo_codificacion" standalone="XX" ?>
Donde:
- version: describe la versión de XML que se está usando. Puede ser «1.0» o «1.1».
- encoding (opcional): permite especificar la codificación de caracteres que se está usando. Por ejemplo UTF-8.
- standalone (opcional): le dice al procesador XML si el documento puede ser leído como un documento único o si es necesario buscar fuera del documento por otras reglas. Puede valer NO o YES.
La declaración tipo de documento contiene un nombre que debe coincidir con el nombre del elemento raíz. Opcionalmente contiene una DTD interna, referencia a una DTD externa o ambas cosas al mismo tiempo:
<!DOCTYPE elemen_raiz declaracion_externa [dtd_interna]>
Las DTD externas pueden ser públicas o privadas. Las públicas se identifican por la palabra clave PUBLIC y tienen la forma siguiente:
<!DOCTYPE elemen_raiz PUBLIC "nombre_DTD" "localización_DTD">
Las privadas se identifican por la palabra clave SYSTEM y tienen la forma:
<!DOCTYPE elemen_raiz SYSTEM "localización_DTD">
Espacios de nombres en XML
Nos podemos encontrar aplicaciones XML en las que un documento contiene elementos y atributos definidos en varios lenguajes. En varios contextos, sobre todo en la Web debido a su naturaleza distribuida, esto podría presentar un problema de colisión y reconocimiento de marcas para el software que los procesa. Se requieren entonces mecanismos que permitan tener con nombres universales cuyo alcance se extienda más allá de los documentos que los contienen. En XML este mecanismo son los espacios de nombres (XML namespaces).
Un espacio de nombres XML es un conjunto de nombres referenciados por una referencia URI, que se usan en XML como nombres de elementos y atributos.
Los nombres de elementos y atributos pueden aparecer entonces como nombres cualificados que consisten en un prefijo y una parte local separadas por : (dos puntos). El prefijo, que tiene una correspondencia con la referencia URI, selecciona un espacio de nombres.
Un espacio de nombres se declara como un atributo. El valor del atributo, una referencia URI, es el nombre del espacio de nombres. El nombre del atributo debe comenzar por el prefijo xmlns: o xmlns. En este último caso el nombre del espacio de nombres es el del espacio de nombres por defecto que exista en el contexto del elemento donde se está incluyendo la declaración. Si el prefijo es xmlns: el nombre puede ser cualquier nombre válido XML.
Un ejemplo de declaración que asocia el prefijo edi a http://ecomerce.org.schema es:
<nom_elem xmlns:edit='http://ecomerce.org.schema'> .......... </nom_elem>
XSL
Básicamente XSL es un lenguaje para la expresión de hojas de estilo. Una hoja de estilo XSL es un fichero que describe como mostrar un documento XML de un tipo dado. Se basa en especificaciones anteriores como DSSSL y CSS, aunque es más sofisticado.
XSL Contiene tres especificaciones:
- XSLT, XSL Transformation, un lenguaje de transformación de documentos XML. Su intención inicial era permitir operaciones de estilo más complejas que las contempladas inicialmente tales como la generación de tablas de contenido o índices, pero ahora se utiliza como un lenguaje de procesamiento de XML de propósito general. Las hojas de estilo XSLT se utilizan por ejemplo para la generación de páginas (X)HTML a partir de datos XML.
- XSL-FO, XSL Formating Objects, un vocabulario para la especificación de formateado.
- XPath, XML Path Language, un lenguaje utilizado por XSLT para referenciar o acceder a partes de un documento XML. También se usa en la recomendación de XLing, XML Linking Language.
XSL especifica como dar estilo a un documento XML utilizando XSLT para describir como el documento se transforma en otro documento XML que utiliza el vocabulario de formateado.
XSLT
Cada documento bien formado XML se puede considerar un árbol cuyos nodos son los elementos y su contenido. Para los propósitos de XSL también deben considerarse nodos los atributos, las estructuras de procesamiento y los comentarios. Básicamente un procesador XML/XSLT toma como fuente un documento XML y construye un árbol denominado árbol fuente y construye otro árbol, el árbol resultado, a partir del árbol fuente. En este proceso puede reordenar nodos, duplicarlos y añadir nuevos objetos de elementos o texto. Los nodos del árbol resultado son objetos de flujo a los que se les ha aplicado estilo. Después se interpreta el árbol resultado para obtener los resultados formateados para su presentación.
Una transformación expresada en XSLT describe las reglas para transformar un árbol fuente en uno resultado y se la llama hoja de estilo pues cuando XSLT realiza una transformación al vocabulario de formateado de XSL (XSL-FO), la transformación funciona como una hoja de estilo.
Una hoja de estilo contiene un conjunto de reglas de plantilla, que dan las reglas para la transformación. Una regla de plantilla tiene dos partes; un patrón, que se compara con los nodos del árbol fuente y una plantilla de la que se crea un ejemplar para que forme parte del árbol resultado.
Los patrones son expresiones XSL, que utilizan la sintaxis de XPath, cuya evaluación va a dar un conjunto de condiciones. Los nodos que cumplen las condiciones son los que se eligen del árbol de entrada.
Las plantillas pueden contener elementos que especifican un literal para incluirlo en el árbol resultado o elementos XSLT que son instrucciones que crearán un fragmento del árbol. Cuando se crea un ejemplar de una plantilla cada instrucción es ejecutada y reemplazada por el fragmento de árbol resultado que crea. Hay elementos que seleccionan y procesan los elementos del árbol fuente que son descendientes del elemento actual (<xsl:apply-templates/>). La construcción del árbol resultado comienza encontrando la regla de plantilla para el nodo raíz y creando una instancia de su plantilla.
Un ejemplo de regla de plantilla es el siguiente:
<xsl:template match="/">
<pre><xsl:apply-templates/></pre>
</xsl:template>
El valor de match es el patrón de la regla de pantilla (/ se corresponde con el nodo raíz) y lo que va entre la apertura y cierre de template es la plantilla.
Una hoja de estilo se representa en un documento XML por un elemento stylesheet que contienen a los elementos template que especifican las reglas de plantilla, además de otros elementos.
El elemento stylesheet debe tener un atributo versión y puede tener como atributos prefijos de extensiones de elementos, como por ejemplo los del espacio de nombres.
Por ejemplo:
<xsl:stylesheet version="1.0" xmlns:xls=http://www.w3.org/1999/XLS/Transform> ......... </xsl:stylesheet>
Algunos de los elementos XSLT son:
- <xsl:apply-templates>: mediante esta instrucción se le dice al procesador que compare cada elemento hijo del nodo actual con el patrón de las reglas de plantilla en la hoja de estilo y si encuentra uno que se ajuste cree un ejemplar de la plantilla de la regla. Puede llevar un atributo select para seleccionar por medio de una expresión los nodos que se van a procesar.
- <xsl:value-of>: tiene un atributo select donde se incluye una expresión. La instrucción crea un nodo de texto en el árbol resultado con la cadena de texto que se obtiene al evaluar la expresión de select y convertir el objeto resultante a una cadena.
- <xsl:if>: el contenido del elemento es una plantilla y tiene un atributo test con una expresión que se evalúa y se convierte el resultado a booleano. Si es cierto se crea una instancia de la plantilla en el contenido, en otro caso no se hace nada.
- <xsl:element>: permite crear un elemento. Tiene un atributo nombre donde se especifica el nombre del elemento. El contenido es una plantilla para los atributos y los hijos del elemento creado.
XSL-FO
XSL-FO especifica un vocabulario para el formateado a través de los llamados objetos de formateado. Utiliza y extiende el conjunto de propiedades comunes de formateado desarrollado conjuntamente con el grupo de trabajo CSS&FP (Cascading Style Sheet and Formating Property).
Cuando un árbol de resultado utiliza este conjunto estandarizado de objetos de formateado, un procesador XSL procesa el resultado y obtiene la salida especificada.
Algunos objetos de formateado comunes son:
- Page-sequence: una parte principal en la que el esquema de diseño (layout) de la página básica puede ser diferente del de otras páginas.
- Flow: una división en una secuencia de página como puede ser un capítulo o una sección.
- Block: como por ejemplo un título, un párrafo, etc.
- Inline: por ejemplo un cambio de fuente en un párrafo.
- Wrapper: un objeto intercambiable, puede utilizarse como block o como inline. Se utiliza sólo para manejar propiedades heredables de los objetos.
- Graphic: referencia un objeto gráfico externo.
- Table-FO: similares a los modelos de tablas HTML.
- List-FO: son listas de objetos. Por ejemplo list-item, list-block, list-item-body.
Algunas propiedades básicas de formateado son:
- Propiedades relativas a márgenes y espaciado.
- Propiedades de fuentes.
- Sangría.
- Justificación.
XPath
El principal objetivo de XPath es el poder dirigirse a partes de un documento XML. Además también se ha diseñado para que pueda utilizarse para comprobar si un nodo se ajusta a un patrón.
El constructor sintáctico básico de XPath es la expresión, que al evaluarse proporciona un objeto de uno de los siguientes tipos básicos:
- Un conjunto de nodos.
- Un valor booleano.
- Un número (de coma flotante).
- Una cadena.
Una clase de expresión es un path de localización. El resultado de evaluar la expresión es un conjunto de nodos que contiene los nodos seleccionados por el path de localización.
Hay dos tipos de paths de localización:
- Relativos: consisten en uno o más pasos de localización separados por /. Los pasos se componen de izquierda a derecha. Por ejemplo child::div/child::xxx selecciona el elemento hijo xxx del elemento hijo div del nodo de contexto.
- Absolutos: consisten en una / seguida, opcionalmente, de un path relativo.
Algunos ejemplos de paths de localización son los siguientes:
- /: selecciona el documento raíz.
- /descendat::xxx: selecciona todos los elementos xxx en el mismo documento que el nodo de contexto.
- child::xxx[position()=1]: selecciona el primer hijo xxx del nodo de contexto.
- child::*: selecciona todos los hijos del nodo de contexto.
XLink y XPointer
XLink, XML Link Language, permite insertar elementos en un documento XML que crean y describen enlaces entre recursos. Su uso más común es para la creación de hiperenlaces. XPointer especifica un modo fácil de entender y conveniente para la localización de documentos XML.
XLink proporciona funcionalidades de enlace avanzadas como:
- Enlaces multidireccionales, se dirigen a varios recursos.
- Asociar metadatos con los enlaces.
- Expresar enlaces que residen en una localización separada de los recursos enlazados.
Los enlaces se implementan por medio de atributos y no por elementos.
XPointer proporciona mejores especificaciones de localización:
- Enlaces que apuntan a un punto específico dentro de un documento, incluso aunque no exista un ID justo en ese punto.
- Granularidad fina que permite apuntar a elementos, cadenas de texto.
- Sintaxis clara para tratar las localizaciones y las relaciones en jerarquías, de forma que es legible por las personas.
Lenguajes de Script
Aunque muchos lenguajes son calificados como lenguajes de script, no hay un consenso sobre el significado exacto del término ni ha sido formalmente definido. Se llaman lenguajes de script a lenguajes como awk, sh de UNIX, Javascript, VBScript, Perl, …
Los lenguajes de script se diseñaron para realizar tareas diferentes de las que realizan otros tipos de lenguajes de programación, como C o C++, y esto lleva a diferencias fundamentales entre los dos tipos de lenguajes.
Los lenguajes de programación tradicionales se diseñaron para construir estructuras de datos y algoritmos empezando desde el principio, desde elementos de computación como las palabras de memoria. Para manejar esta complejidad suelen ser fuertemente tipados.
Frente a esto, los lenguajes de script se diseñaron para unir componentes. Asumen la existencia de un conjunto de potentes componentes y se centran generalmente en poner juntas estas componentes. Además suelen ser débilmente tipados, el tipo se determina en tiempo de ejecución, para simplificar la conexión entre componentes.
Otra diferencia entre los dos grupos de lenguajes, los de script frente a los que no reciben esta denominación, es que los lenguajes de script son generalmente interpretados en vez de compilados. Los lenguajes interpretados eliminan los tiempos de compilación durante el desarrollo y hacen a las aplicaciones más flexibles al permitir que se genere código fácilmente en tiempo de ejecución.
Estas características producen, generalmente, código que es menos eficiente. Sin embargo, el rendimiento no suele ser un aspecto fundamental en un lenguaje de script. Los lenguajes de script se dirigen fundamentalmente a áreas donde la flexibilidad y un desarrollo rápido son mucho más importantes que el puro rendimiento. Las aplicaciones en lenguajes de script suelen ser más pequeñas que las aplicaciones en otros lenguajes de programación y el rendimiento de una aplicación de scripts está dominado por el rendimiento de sus componentes, que generalmente están implementadas en algún otro tipo de lenguaje de programación.
Los dos grupos de lenguajes son complementarios, y las principales plataformas de computación han proporcionado tanto lenguajes de programación como de scripts desde los años 60. Mientras que los lenguajes de programación que podríamos denominar de sistemas o tradicionales son buenos para producir implementaciones eficientes de funcionalidades críticas con respecto al tiempo, los lenguajes de script son buenos para poner juntas componentes de distinta funcionalidad.
Sin embargo la existencia de máquinas cada vez más rápidas, la existencia de mejores lenguajes de scripts, la importancia creciente de las interfaces gráficas de usuario y de las arquitecturas de componentes, y sobre todo el crecimiento de Internet, han incrementado enormemente la aplicabilidad de los lenguajes de script.
Podemos citar entre las características típicas de los lenguajes de script, aunque no siempre las tienen todas:
- Interpretados.
- Débilmente tipados.
- Asignación dinámica de memoria con liberación automática de la misma.
- Potentes capacidades para la manipulación de cadenas (expresiones regulares).
- Procedurales y con extensiones de orientación a objetos.
- No es necesario que el usuario del lenguaje defina clases o métodos.
- Utilizan un método de invocación de métodos muy simple, no es necesario especificar los paths de los objetos para acceder a los métodos.
Entre los lenguajes de script más comunes podemos citar Javascript, Perl, VBScript, …
Aplicación de los lenguajes de script a internet
Los lenguajes de script se han utilizado en Internet para un aspecto fundamental, añadir interactividad y dinamismo a las páginas web.
El método más antiguo para añadir esta interactividad es mediante programas que utilizan la interfaz CGI (Common Gateway Interface). CGI es un protocolo estándar que especifica como pasar información desde una página web, a través de un servidor web, a un programa y devolver información desde el programa a la página en el formato apropiado. Los lenguajes de script, sobre todo Perl, son los más comúnmente utilizados para escribir estos programas CGI.
Pero CGI presenta ciertos problemas de ineficiencia. Por un lado los programas CGI se ejecutan fuera del servidor web y además están diseñados para manejar sólo una petición y terminar su ejecución después que han devuelto sus resultados al servidor.
Hoy en día se utiliza sistemas que toman la forma de componentes que se apoyan en APIs específicas del servidor para interactuar directamente con el proceso del servidor. Conectándose como un subproceso al servidor Web se evita mucha de la sobrecarga de los programas CGI convencionales.
La generación de contenido dinámico del lado del servidor requiere que el servidor procese las peticiones en tiempo de ejecución para dar una respuesta apropiada a la petición, así que se necesitan instrucciones para ejecutar este procesamiento y por tanto alguna forma de programarlas.
Otra forma de añadir interactividad y dinamismo es mediante scripts del lado del cliente, fundamentalmente usando Javascript. El código de script se introduce directamente o se referencia en el documento HTML y se ejecuta cuando se carga la página o como respuesta a otro tipo de eventos.
Un ejemplo de uso de scripts en Web es la validación de formularios (uno de los motivos originales para el desarrollo de Javascript). La validación de formularios es el proceso de comprobar la validez de los datos introducidos por el usuario antes de enviarlos al servidor.
Con la aparición de la generación 4.x de los navegadores se introdujo el concepto DHTML, HTML dinámico, que describe la capacidad de manipular dinámicamente los elementos de una página a través de la interacción:
- HTML: la versión 4 introdujo dos cosas importantes, CSS y DOM.
- CSS: con CSS se tiene un modelo de estilo y layout para documentos HTML.
- DOM (Document Object Model): proporciona un modelo del contenido para documentos HTML.
- Javascript (y VBScript): permite codificar scripts que controlen los elementos HTML.
